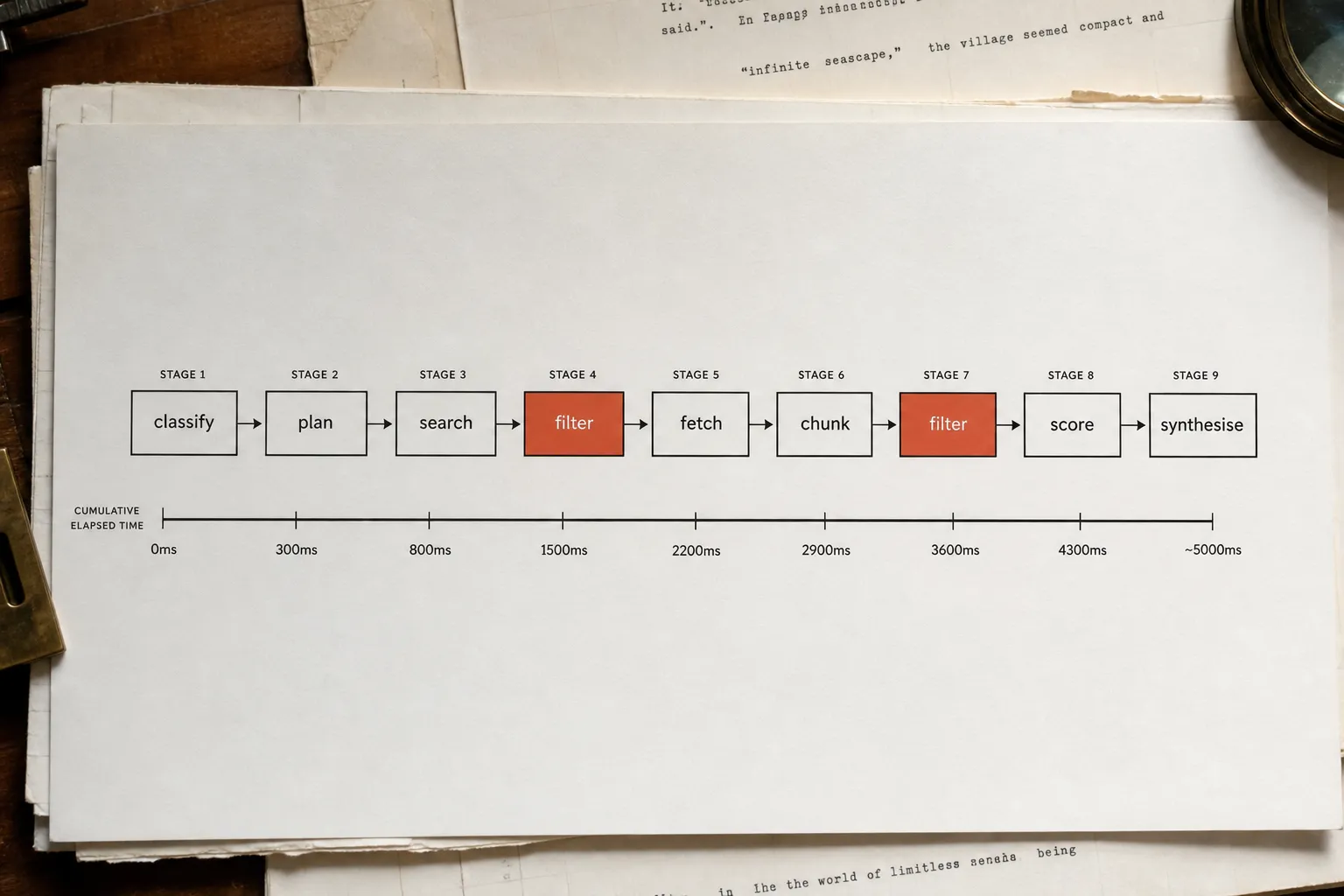
The GEO/AEO consensus - add llms.txt, clean up your schema, rewrite your copy to sound authoritative - rests on a single untested assumption: that the crawler will bother to read your signals. It won't. Semrush's server-log test on Search Engine Land recorded zero visits from GPTBot, PerplexityBot, ClaudeBot, or Google-Extended to the llms.txt file across ten weeks of observation in 2025. The polite handshake you spent an afternoon setting up went unacknowledged. The only reliable fix is not a content fix. It's an infrastructure fix, and it lives at the network edge.
01The passive strategy and why it fails.
LLMs.txt was proposed in 2024 and had accumulated 844,000 adopting domains by mid-2025. The adoption curve was real. The crawler behaviour was not. Semrush's own log data from Search Engine Land shows no major AI crawler requested the file in the period from mid-August to late October 2025. A separate August 2025 audit of 1,000 Adobe Experience Manager domains, run across 30 days of CDN logs, reached the same conclusion: Google's desktop crawler accounted for 95% of llms.txt hits; every LLM crawler was effectively absent.
Robots.txt fares no better. TollBit's traffic analysis found that 13.26% of AI bot requests in Q2 2025 outright ignored robots.txt directives - up from 3.3% just two quarters earlier in Q4 2024. The direction is clear. These bots are not adversarial, exactly, but they are not cooperative either.
The underlying problem is structural. Passive strategies - llms.txt, schema markup, content rewrites - rely on crawlers honouring your intent. Infrastructure strategies enforce that intent regardless of what the crawler chooses to read. That distinction is the whole argument.
02How big the bot audience already is.
The opportunity cost of getting this wrong is real, not abstract. Automated traffic crossed 51% of all global web traffic in 2024 for the first time in a decade, per the Imperva 2025 Bad Bot Report. The majority of requests arriving at your origin are already non-human. The question is whether you are serving that majority anything useful.
Among AI crawlers specifically, the growth rates are staggering. Cloudflare's Radar data comparing May 2025 to May 2024 shows GPTBot up 305%, ChatGPT-User up 2,825%, and PerplexityBot up 157,490%. User-action crawling - bots fetching live pages in response to a real user's question, right now - grew more than 15 times over the same period. This is the category where your citation odds actually live: a user asks ChatGPT something, the model triggers a live fetch, and your page either answers the question clearly or returns several seconds of hydration noise. Per HUMAN Security's 2026 State of AI Traffic report, overall AI bot traffic grew 187% across 2025 while human traffic grew just 3.1%. Agentic bot traffic - AI agents acting autonomously, not just reading - grew nearly 8,000% year-over-year.
That last number deserves its own sentence. ClaudeBot operates at a 38,000:1 crawl-to-referral ratio at its worst, meaning the vast majority of its crawls result in zero traffic back to you. GPTBot's ratio sits at roughly 400:1. Being crawled is necessary but nowhere near sufficient. What matters is whether the content you serve gets extracted cleanly enough to influence a model's output.
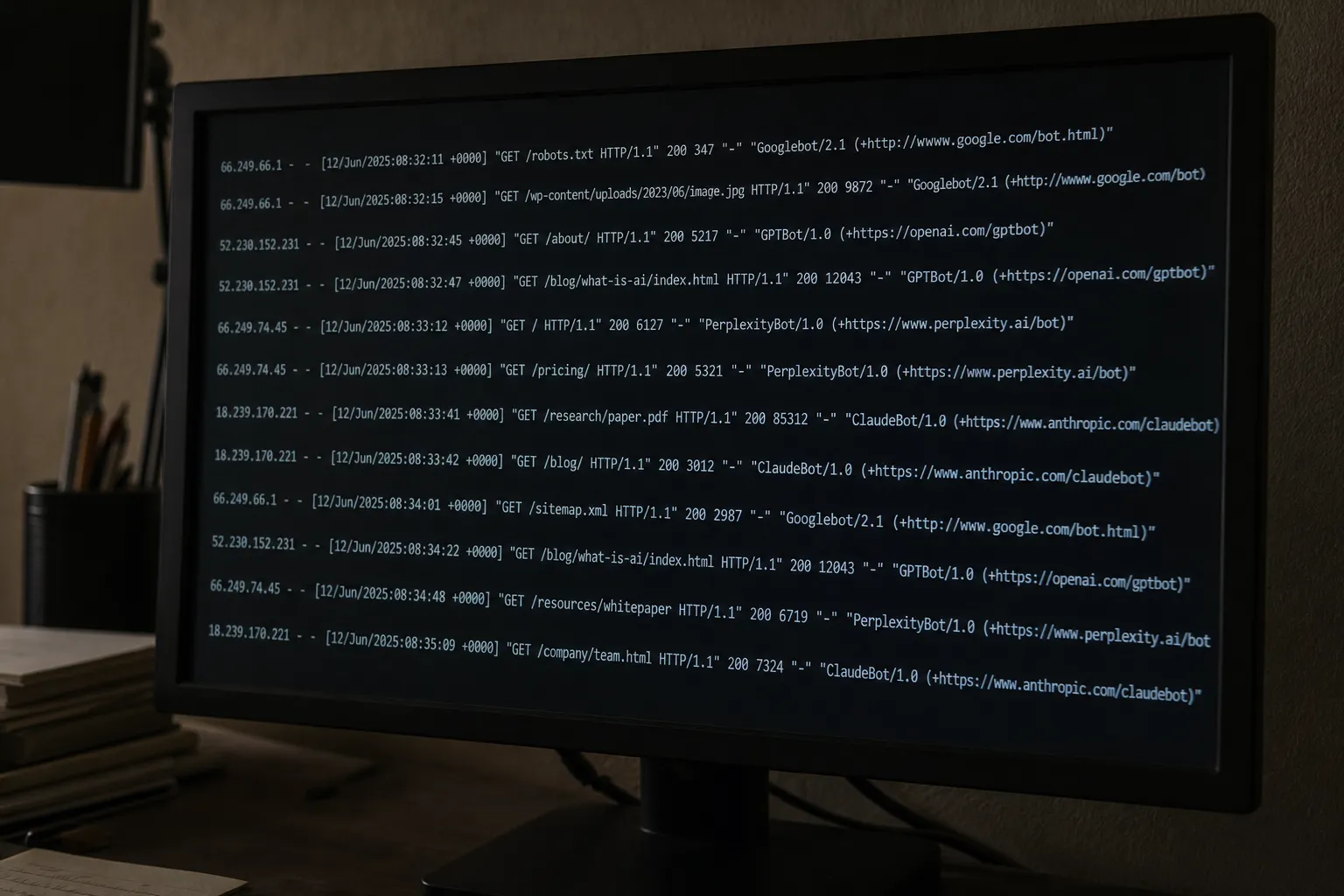
03What AI crawlers actually want from your HTML.
The technical gap between what a typical SaaS marketing page delivers and what a crawler needs is not subtle. AI crawlers don't render JavaScript. They don't store cookies. They send bare headers and expect a document in return. What they receive from a standard single-page application is thousands of lines of script tags, navigation components, cookie consent dialogs, and deferred module loading - before a single word of product copy appears.
The April 2026 research from Cloudflare and ETH Zurich, published as "Rethinking Web Cache Design for the AI Era", identified three structural properties of AI bot traffic that degrade CDN performance: high unique URL ratios, broad content diversity, and crawling inefficiency. Their proposed fix - a dedicated cache tier for AI traffic - is an acknowledgement that AI crawlers are a fundamentally different traffic class requiring a different infrastructure response.
The content side of this is well-documented. HubSpot's GEO research found that LLMs are 28–40% more likely to cite content with clear hierarchical structure: headings, bullet points, tables. The Princeton, Georgia Tech, and Allen Institute GEO paper - the peer-reviewed benchmark behind most of what the industry now calls GEO - found that the best content-optimisation methods improved citation visibility by 22% on position-adjusted word count and 37% on subjective impression. The qualifier buried in that finding: only when the content was structured for extraction to begin with.
A purpose-built stripped page outperforms an optimised human page every time, with one condition. The crawler has to receive it.
04The edge interception model.
Edge computing positions logic at the network boundary, before requests reach your origin. A request arrives, the edge node classifies it, and two different responses go out depending on what the classifier decides. This is not new architecture; it is the standard pattern for things like geolocation redirects and A/B testing. Applying it to bot traffic is the natural next step.
Cloudflare's February 2026 "Markdown for Agents" feature demonstrates the model working at production scale: AI systems receive clean, token-efficient content at the same URL that human visitors use for the full experience. The routing decision happens in under a millisecond at the edge node. No origin infrastructure changes required.
The classifier itself matters. Cloudflare's AI Crawl Control combines user-agent strings with behavioural signals - crawl speed, sequential access patterns - TLS fingerprinting, and IP range intelligence, run through ensemble machine-learning models to keep false-positive rates low. User-agent sniffing alone is insufficient, and this is not a minor caveat.
Momentic's Winter 2025 crawler analysis documents the problem precisely: ChatGPT Atlas uses a standard Chrome user-agent string, making it indistinguishable from human browser traffic in your server logs. OpenAI Operator runs in a remote Chrome instance that appears identical to a regular user session. If your detection logic relies only on checking for "GPTBot" in the user-agent header, you are missing a growing fraction of the most consequential traffic - the agentic browsers acting on behalf of real users right now.
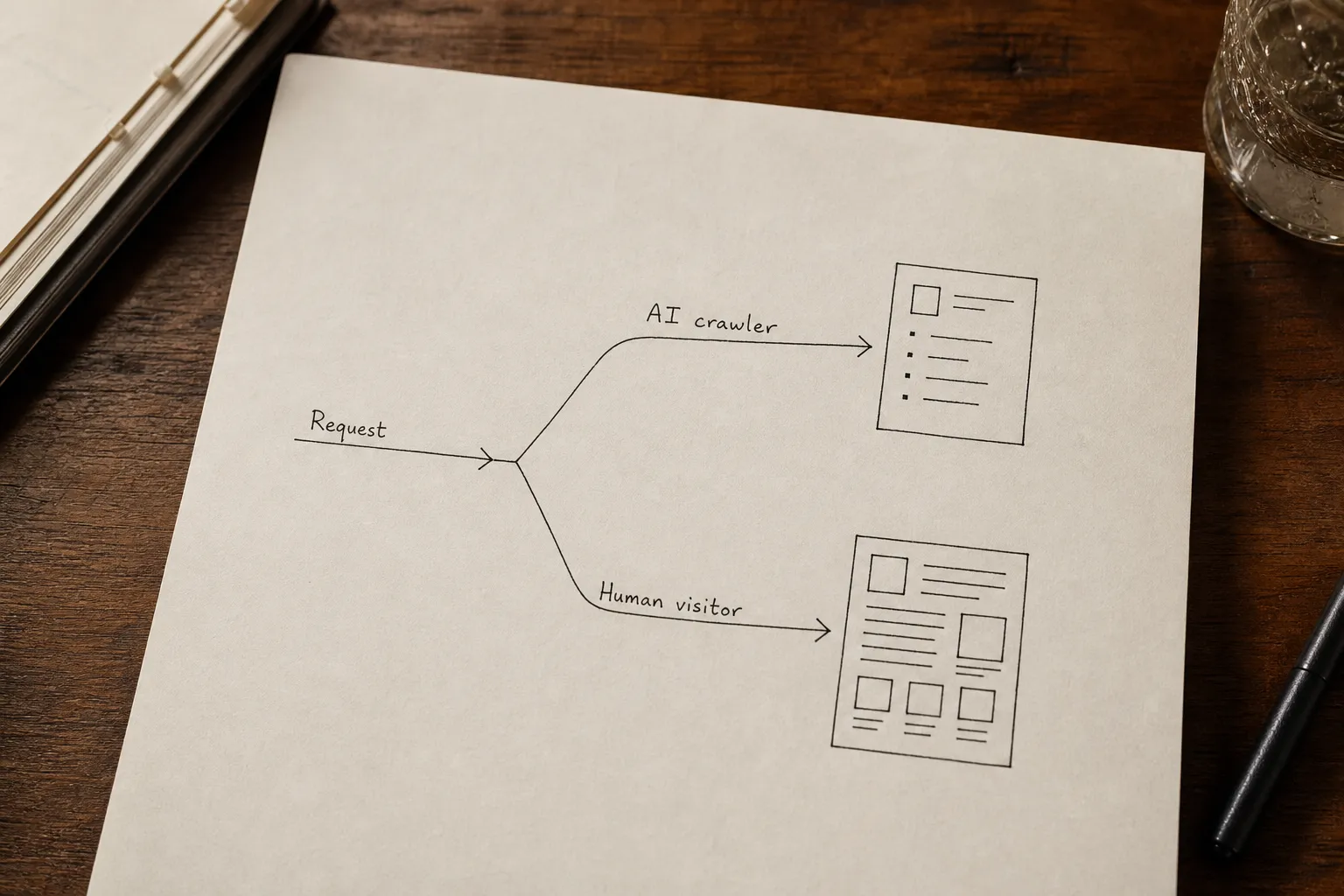
A word on the cloaking question, because it will come up: serving different content to deceive a search engine is cloaking and violates Google's guidelines. Serving the same semantic content with presentation overhead stripped out is not. The distinction is whether you are hiding information from the crawler or simply removing the JavaScript navigation and hero imagery that the crawler cannot use anyway. Edge-served agentic pages should contain everything the human page contains - every claim, every product detail, every source - with the rendering layer removed.
The architecture is simple to state. Incoming request hits the edge node. The bot classifier runs. Matched AI traffic routes to a stripped, schema-first HTML variant: no navigation, clean heading hierarchy, FAQ structured data, statistics cited with sources. Human traffic routes to the full experience. Both come from the same URL. Neither audience knows the other exists.
05Why content alone can't win the citation race.
Forty-seven percent of brands still have no deliberate GEO strategy as of October 2025 data. The early-mover gap is real and it is large. But winning requires more than having a strategy; it requires a strategy that can actually reach the crawler.
The Conductor AEO/GEO Benchmarks Report - built on 13,770 domains, 3.3 billion sessions, and 100 million AI citations - measures AEO success in citation frequency, not click-through rate. The game is being cited, not being clicked. GEO-ready content delivered inside a JavaScript SPA still arrives as noise. The content work and the infrastructure work are not substitutes; the content work only pays off when the infrastructure work ensures the crawler receives it.
Evil Martians' February 2026 analysis frames this cleanly: the strongest case for stripped, AI-specific pages is not that Markdown is inherently superior to HTML, but that most real-world HTML carries such a high noise-to-signal ratio that even well-structured copy gets lost in transit. Schema markup correlates with 30–40% higher visibility in AI-generated answers across multiple GEO studies. Edge-served pages can enforce schema fidelity without depending on the CMS to generate it correctly on every publish.
The bottleneck is delivery. The writing is table stakes.
See your AI crawler traffic before you change anything else.
Klove pulls 30 days of bot traffic from your CDN logs and shows you exactly which crawlers are hitting which pages - and what they're receiving.
06Three things to build this week.
Start with your server logs, not your analytics platform. Google Analytics filters AI bot traffic by design. Pull 30 days of raw CDN or WAF logs and count requests carrying the user-agent strings for GPTBot, ChatGPT-User, ClaudeBot, PerplexityBot, Meta-ExternalAgent, and Applebot. This is your baseline. Do not change anything until you have it.
Then identify three pages with the highest AI-citation value: your homepage, your primary product or use-case page, and your most-linked blog post. These are the pages a model reaches for when a buyer asks a category question. Build stripped, schema-first HTML variants for each - no navigation, no hero images, clean H1-through-H3 hierarchy, FAQ-structured data using schema.org/FAQPage, named statistics with inline source attribution. The variants can live at internal URLs initially; the edge routing exposes them to crawlers without surfacing them to humans.
Deploy a bot-detection rule at the edge. Cloudflare Workers, Fastly Compute, or the equivalent at your CDN of choice all support this. Match on verified AI crawler user-agent strings combined with known data-centre IP ranges for the major AI labs. Route matched traffic to your stripped variants. Log every match with the originating user-agent, the requested URL, and a timestamp. Review the match rate after seven days - it will almost certainly be higher than your analytics data suggested. Check session duration and bounce behaviour on the human traffic side to confirm no legitimate visitors are being mis-classified.
One more thing: set up llms.txt anyway. It costs an hour and signals intent. If crawler adoption hardens over the next twelve months - and Anthropic and OpenAI have said publicly they intend to improve compliance - you want to have been there first. Just do not let it carry the weight of your AEO strategy. It cannot bear it.
07Where this architecture goes next.
Agentic bot traffic grew nearly 8,000% in 2025, per HUMAN Security. The thing worth understanding about that number is that it is not describing crawlers in the traditional sense. Agentic browsers are booking travel, comparing software pricing, reading cancellation policies, and completing checkout flows - on behalf of real users, autonomously. They are not reading your page for training data. They are reading it because a user asked them to do something.
ChatGPT Atlas is indistinguishable from Chrome in server logs. OpenAI Operator runs in a remote browser that presents as a standard human session. The detection problem will only harden from here as agentic browser adoption broadens and these tools adopt more human-like browsing patterns to avoid friction.
The industry's answer to this is moving toward cryptographic identity. Cloudflare published a bot and agent authentication registry format in October 2025 - a mechanism for crawlers to present verified credentials before you decide what to serve them. This is the endpoint of the current trajectory: instead of inferring intent from behaviour, you read a signed token. The edge is the only layer where that handshake is economically feasible at scale.
The two-audience web is already a three-audience web: human visitors, training crawlers, and agentic browsers acting on user intent. Each class needs a different optimised response. Gartner projects up to 25% of searches shifting to generative engines by 2028. The sites building agentic infrastructure in 2025 and 2026 are not just improving their citation odds today - they are establishing the source preferences that models will default to before most competitors have finished their content rewrites.
The passive strategy trusts the crawler to cooperate. The edge strategy does not need it to.

Prior to founding Klove, Michael spent over a decade at the intersection of engineering, growth marketing, and revenue operations - building GTM systems for high-growth B2B SaaS companies.