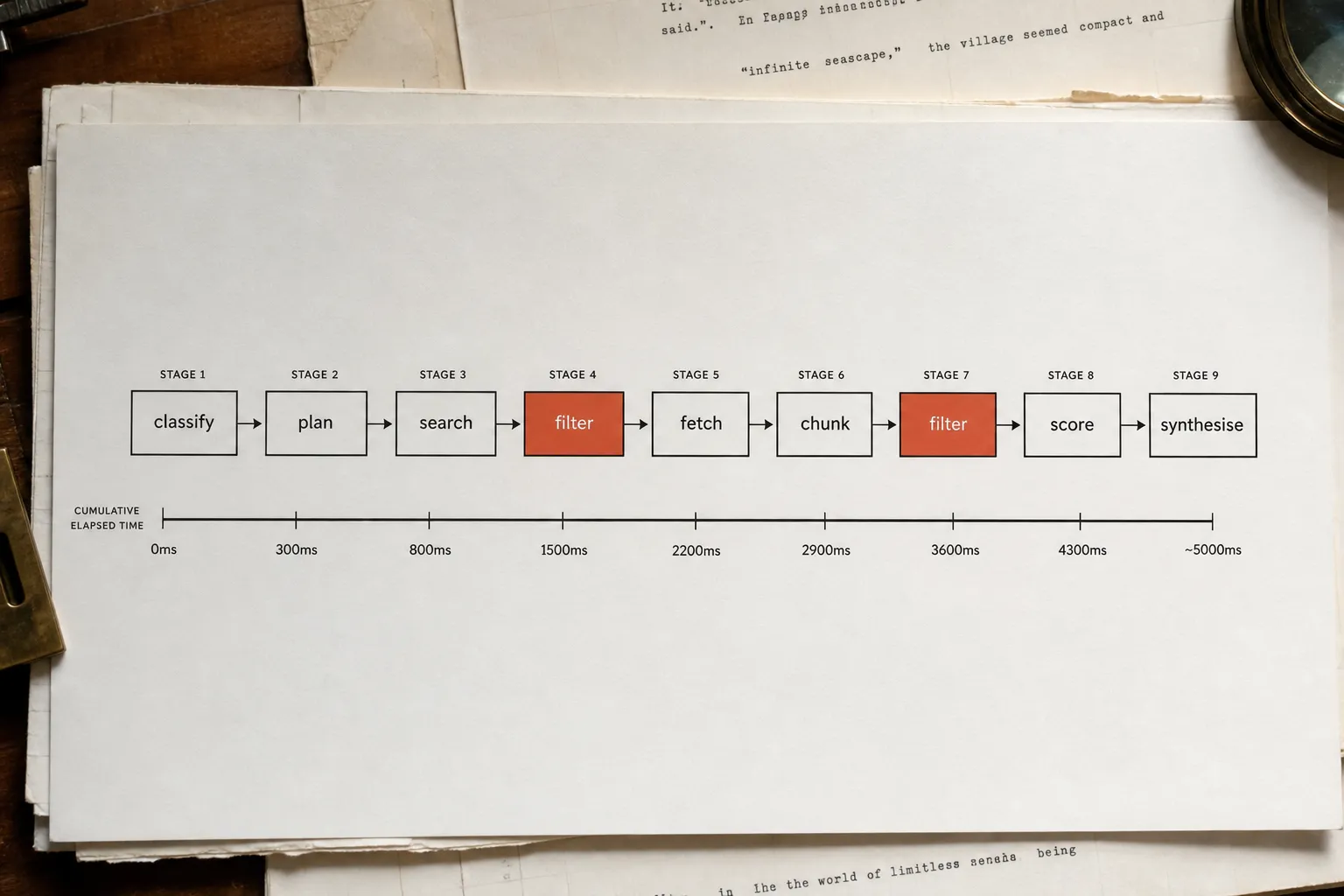
Most sites doing "AI SEO" have the sequence backwards. They're polishing their prose while their pages return a 403 to GPTBot, or serving a JavaScript shell that renders nothing useful to a headless crawler. The content advice is sound. It's just third in line. Fix crawl access first, fix extractability second, and only then does the rest of the playbook matter. This post runs the steps in that order, because AI-referred visitors convert at a rate that makes the sequence worth getting right - and most sites are disqualifying themselves at step zero.
01Why is AI citation optimization is not the same as SEO?
The intuition that AI citations follow organic rankings made sense in 2024. It doesn't hold in 2026. By early 2026, only 38% of pages cited in Google AI Overviews also ranked in Google's top 10 - down from 76% in July 2025, according to Ahrefs' study across 863,000 keywords. That collapse happened in under a year.
The decoupling is even sharper across AI assistants. Only 12% of links cited by ChatGPT, Gemini, and Copilot rank in Google's top 10 for the same query; 31% rank outside the top 100 entirely. The content layer driving AI citations is invisible to traditional SEO tooling.
The traffic volume is smaller than organic, but the per-session value is higher.
Google's ranking system rewards documents. AI retrieval systems reward passages - clean, attributable, extractable chunks that a language model can safely repeat without hallucinating the source. A page that ranks well in Google may be structurally opaque to an AI. A page that barely registers in organic search may be perfectly formatted for extraction. These are separate retrieval systems with different inputs. Treating AI citation as a downstream SEO outcome keeps most teams measuring rankings while their competitors get cited.
02Step 1: make your pages actually reachable.
Before any content decision matters, the crawler has to get in. 63% of ChatGPT agents leave immediately on landing - HTTP errors, redirects, slow loads, CAPTCHAs, and WAF rules that flag bot user-agents are the primary causes, according to Search Engine Land's October 2025 analysis. More than half of all AI crawl attempts fail before a single word of content is read.
The rendering problem is equally common. 46% of ChatGPT bot visits begin in reading mode - a plain HTML view with no CSS, no JavaScript, and no schema. If your product page depends on a React component to populate the pricing section, or your blog loads content via client-side fetch, the AI crawler sees a blank container. The content exists. The crawler doesn't receive it.
The test is simple: disable JavaScript in your browser and reload your homepage, your product page, and your three most-trafficked posts. Whatever disappears is invisible to most AI crawlers. For many SaaS sites, this test removes most of the page.
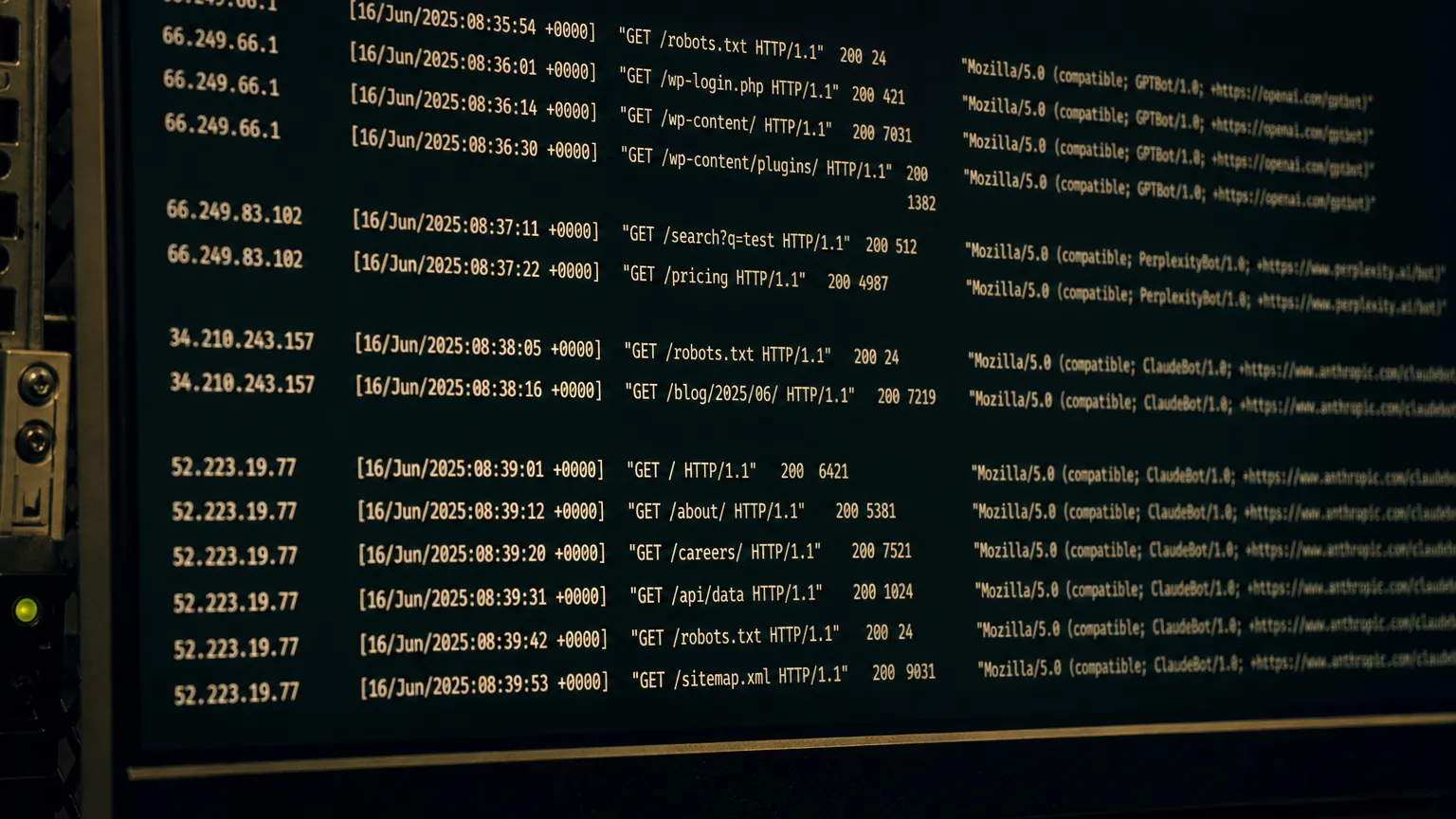
Then check your server logs. Search for GPTBot, ClaudeBot, PerplexityBot, Google-Extended, and OAI-SearchBot. Confirm each is reaching your key URLs with a 200 response. Accidental blocks in robots.txt or rate-limiting rules in WAF configurations are common, and they're silent. No crawler error surfaces to the site owner. The bot just stops visiting.
Klove solves this at the edge: machine-readable parallel pages served directly to AI crawlers, bypassing the production render stack entirely. The production site doesn't change. What the crawler receives does.
03Step 2: structure content so AI can extract an answer.
Crawlability is access. Extractability is what happens once the crawler is inside. They're different problems, and most content advice conflates them.
The position effect is significant. 44.2% of all LLM citations come from the first 30% of page content; only 24.7% from the final third. Front-load the answer. Put the claim before the supporting argument. An AI isn't reading for narrative arc. It's scanning for a passage it can safely repeat.
Length correlates with citation rate, but not because longer content is better. Articles above 2,900 words are significantly more likely to be cited by ChatGPT than those under 800 words. The mechanism is density: longer pieces contain more citable passages, more specifics, and more structured subarguments that extract independently of surrounding text. Length without density is noise.
Section structure matters more than most teams expect. Pages organised into 120–180-word sections earn substantially more ChatGPT citations than pages with very short sections under 50 words. A section that's too short reads as a fragment. A section that runs 600 words reads as an article, hard to extract a single clean claim from. The 120–180-word range is long enough to make a complete point, short enough to lift intact.
Recency is a ranking factor in AI retrieval. Content updated within the past three months is twice as likely to be cited as older pages. This requires a refresh cadence most editorial calendars don't support and one that no amount of one-time optimisation sustains. The sites that hold citations update the claims, not just the dates.
Extractability is a structural property, not a writing style. Use specific numbers over vague claims. Use clear, declarative sentences that stand alone out of context. Use headings that name the claim, not just the topic. An AI isn't impressed by nuanced prose. It needs a passage it can attribute.
04Step 3: build off-site authority the right way.
On-site optimisation has a ceiling. The AI can't treat a single domain as sufficient consensus for a claim. It needs to see the same assertion echoed across multiple credible, distinct sources before it will confidently cite any of them.
Third-party coverage carries direct weight. Brands are 6.5x more likely to be cited in AI answers through third-party sources than through their own domains. Publishing on your own site is necessary but not sufficient. Distributing content to a wide range of publications can increase AI citations by up to 325% compared to publishing only on your own domain, according to Stacker's December 2025 study tracking actual citation frequency.
Wikipedia carries direct weight in ChatGPT's citation stack. It is the most-cited source in ChatGPT responses at 7.8% of all citations, according to Profound's June 2025 analysis. A well-sourced Wikipedia entry, or even a Wikipedia citation linking to your primary research, functions as a trust anchor. This reflects the training data reality. Wikipedia appears in the model's knowledge base at a density no SaaS blog can match.
Third-party review platforms are the trust anchors AI uses for commercial claims. G2, Capterra, and Trustpilot profiles increase citation likelihood by approximately 3x. For B2B companies, this is one of the highest-leverage distribution investments available because the platforms already have domain authority and the AI's trust. You're populating them with accurate, specific data.
The pattern holds across categories: publish and pray fails because no single domain is treated as consensus. Get the same claim into four or five credible, distinct sources before the AI will cite any of them with confidence. Start with your best original data point, then place it in a DA 60+ publication, your G2 profile, and wherever your industry's Wikipedia equivalent lives.
05Step 4: tune per platform - they are not the same engine.
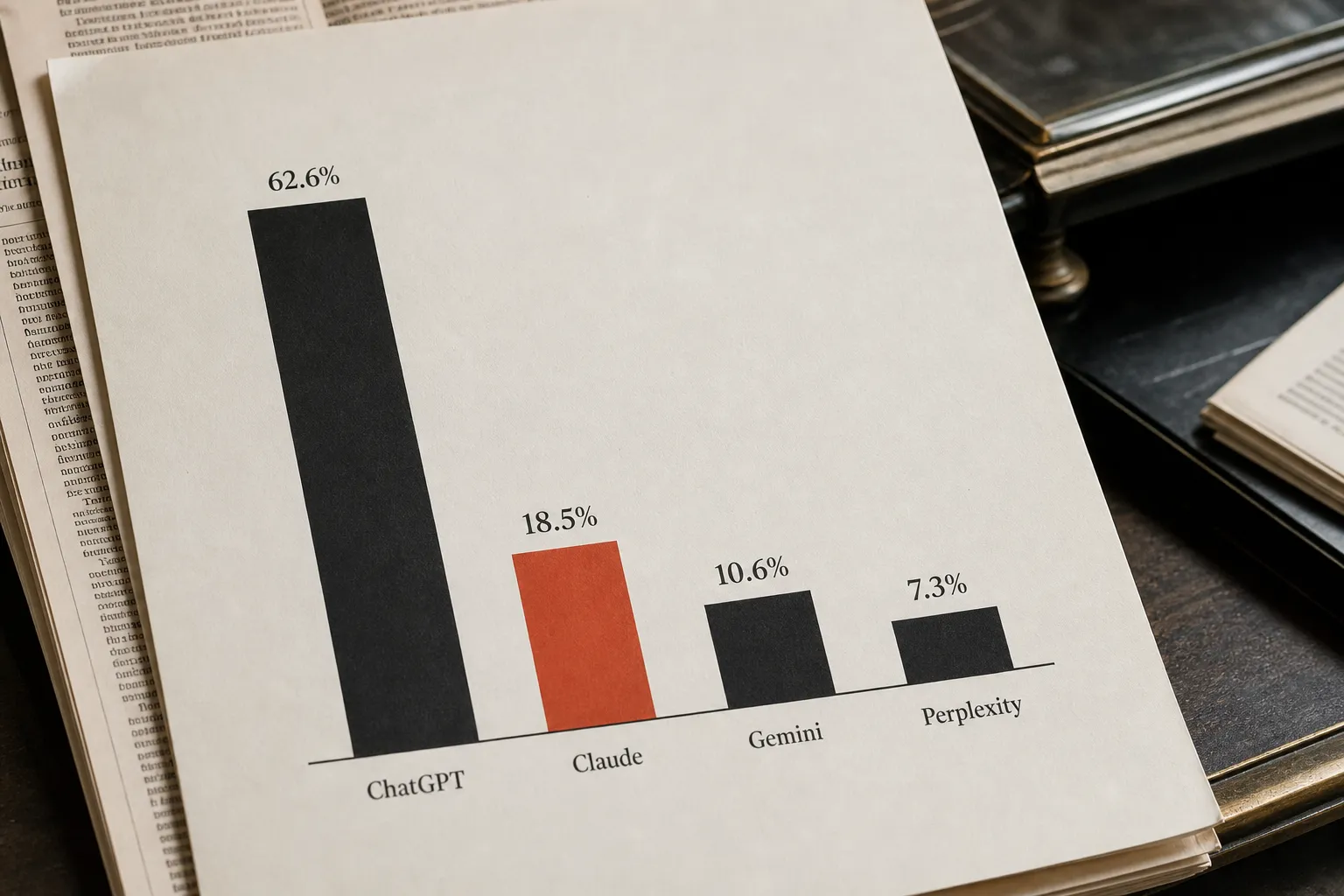
A ChatGPT-only strategy already misses a third of the landscape. ChatGPT's share of B2B AI referrals fell from 89% in mid-2025 to 62.6% by April 2026; Claude is now the second-largest source at 18.5%, according to Goodie AI's April 2026 traffic report. Gemini accounts for 10.6%, Perplexity for 7.3%. The distribution is fragmenting faster than most optimisation strategies have adapted.
Each platform has different retrieval logic, and the citation source mix reflects that. Yext's analysis of 6.8 million citations found that Gemini sources 52.15% of its citations from a brand's own domain. It trusts what you say about yourself, filtered through Google's index. ChatGPT sources 48.73% from third-party directories. It trusts what the internet broadly agrees on. Perplexity runs live retrieval on every query and weights recency heavily.
That recency weighting on Perplexity is a cliff, not a decay curve. Content updated within 30 days carries an 82% citation rate on Perplexity; content older than 180 days drops to 37%. A page you optimised once and left loses Perplexity visibility every month it sits unchanged.
The cross-platform overlap is smaller than most teams assume. Only 11% of domains are cited by both ChatGPT and Perplexity, from an analysis of 680 million citations. A brand that performs well on Gemini may be near-invisible on Perplexity, and vice versa.
Think of these as three separate editorial desks, each with different sourcing standards. Gemini is weighted toward your own authoritative content, indexed through Google. Perplexity rewards fresh, specific, frequently updated material. ChatGPT rewards cross-domain consensus and third-party directory presence. The tactics aren't contradictory, but the emphasis is different, and measuring only one platform's citations will give you a systematically wrong picture of your actual AI visibility.
06Step 5: make your pages agent-friendly, not just crawlable.
Citation optimisation solves for being referenced in an answer. That's the floor, not the ceiling.
92% of ChatGPT agents use the Bing Search API rather than live SERPs, according to Search Engine Land's October 2025 analysis. The agent retrieves pages and browses them, not just querying a model for a summary. It reads content, follows links, and increasingly takes action.
The agentic layer matters because AI is moving from information retrieval toward transactional mediation. AI agents are projected to mediate trillions of dollars of global commerce by 2030. The agents doing that work need to read, navigate, and act on pages, not just scan them for quotable passages. A page well-structured for citation is not necessarily a page an agent can transact on.
A machine-readable parallel page strips rendering friction from the citation path. An agentic page layer goes further. It gives the AI a version of the page it can interact with. That means completing forms, comparing options, surfacing the specific data the agent's task requires, without depending on JavaScript hydration, session cookies, or UI components that don't exist in a headless context.
Most sites are optimising for the first version of AI interaction: the static question-and-answer. The infrastructure for the second version - agent-navigable pages that complete tasks - is what separates the next phase of AI visibility from what most playbooks currently describe.
See what AI crawlers actually receive from your site.
Klove runs a live crawl of your key pages and shows you exactly what GPTBot, ClaudeBot, and PerplexityBot see - then walks through how edge-served parallel pages change that. Thirty minutes, no prep required.
07Three things to fix this week.
Measurement comes last in this list, but it anchors everything. 78% of marketing teams have zero AI visibility tracking. Before investing in tooling, establish a manual baseline. You cannot improve what you cannot see.
1. Run the JavaScript-off test. Disable JavaScript in your browser and reload your homepage, your product page, and your top three blog posts. Note what disappears. Any content that vanishes is invisible to most AI crawlers, regardless of how well it is written or how well it ranks in organic search. This test costs nothing and takes ten minutes.
2. Audit your server logs for AI crawler responses. Search for GPTBot, ClaudeBot, PerplexityBot, Google-Extended, and OAI-SearchBot. Confirm each is returning a 200 response on your key URLs. A 4XX or 5XX response means the crawler is being actively blocked or erroring out. A redirect loop means the bot is cycling without receiving content. Fix these first. No content optimisation matters if the crawler cannot get in.
3. Redistribute your single best-performing page. Identify the page on your site most likely to be cited, then get the underlying claim into more places. Submit a guest post or data story based on it to a DA 60+ publication. Update your G2 and Capterra profiles to reference the same specific claim. Check whether your Wikipedia presence cites the underlying data. One well-placed external citation of your original research does more for AI visibility than ten additional paragraphs on the original page.
Start with step one. The JavaScript-off test either confirms your pages are structurally sound or reveals a rendering problem that makes every other step in this playbook moot. Get that answer first.

Prior to founding Klove, Michael spent over a decade at the intersection of engineering, growth marketing, and revenue operations - building GTM systems for high-growth B2B SaaS companies.