Your site might be invisible to every AI that matters - not because your content is weak, but because the crawler never got through the door. An analysis of over 500 million GPTBot fetches found zero evidence of JavaScript execution. If your pages are rendered client-side, that is not a rendering quirk to log for later. It is a structural exclusion from AI search, operating quietly, right now, on every URL you care about.
01The problem is not your content, it's the door.
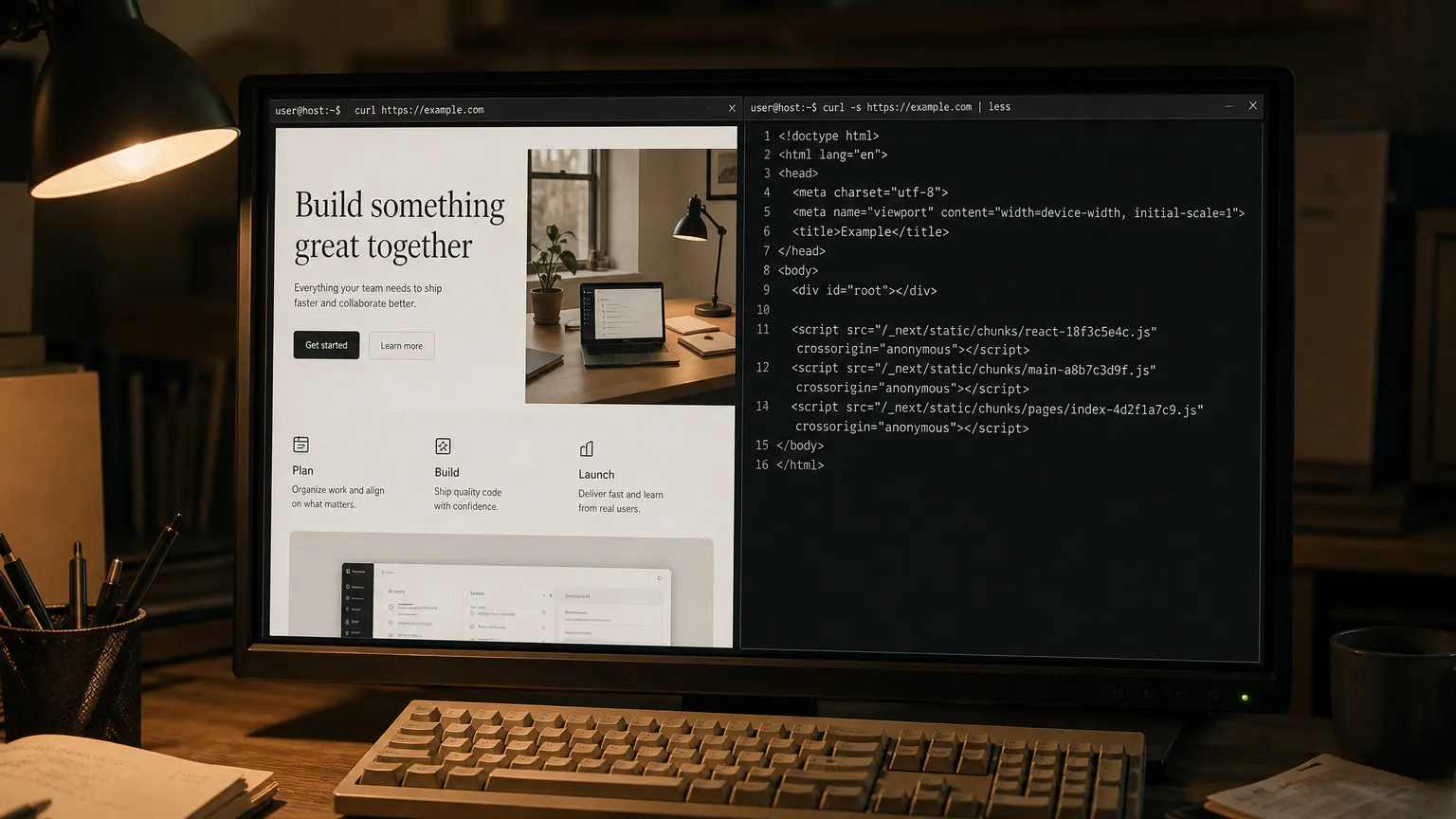
GPTBot, ClaudeBot, and PerplexityBot do not execute JavaScript. This is not a temporary limitation waiting on a product roadmap. It is a deliberate architectural constraint: these crawlers are built for speed and scale, not for running a browser engine against every React bundle they encounter. The consequence is binary. A client-side rendered single-page application sends an AI crawler an empty shell - a root <div> and a list of script tags. Nothing is citable because nothing is there.
Time compounds this problem. AI crawlers impose hard timeouts of one to five seconds. Googlebot allocates roughly 180 seconds of patience per page, enough to wait out hydration cycles and lazy-loaded content. AI crawlers will not. They arrive, request the URL, and leave with whatever the server returns in the first few seconds. If your content is behind a JavaScript waterfall, they leave with nothing.
The pattern keeps repeating: teams spend months refining their content strategy for AI citations - adding statistics, restructuring headings, commissioning longer editorial pieces - and then wonder why citation rates do not move. The answer, almost always, is that the crawler never reached the content they refined. A React SPA can rank on page one of Google while being entirely blank to every other major AI crawler. Google has its own rendering pipeline. Nobody else does.
This is the real bottleneck. Not what you wrote. Where it lives.
02The scale of what's crawling your site right now.
Stop on the traffic numbers before dismissing this as a niche concern. GPTBot's share of AI crawler traffic grew from roughly 5% to 30% in a single year, according to Cloudflare Radar data tracking May 2024 through May 2025. PerplexityBot recorded a 157,490% increase in raw requests over the same period. These are not gradual shifts on a slow curve. This is a step change in who is hitting your server and what they are trying to do with what they find.
AI-referred visitors convert at between 4.4 and 23 times higher rates than organic search visitors, depending on the study and segment. The traffic is still relatively small in volume. The value per session is disproportionate. These are buyers who have already asked an AI a specific question, received a specific recommendation, and then clicked through. The funnel is pre-qualified before they arrive. Missing that cohort is not a statistical detail - it is the highest-intent traffic channel on the web, and it is growing at several hundred percent a year.
ChatGPT processes around 2 billion queries daily. AI platforms generated 1.1 billion referral visits in June 2025 alone, up 357% year-on-year. The window is not opening gradually. It has opened.
03What GEO gets right - and where it stops short.
The research on generative engine optimisation is real and the gains are meaningful. The Princeton study published at KDD 2024 found that structured content optimisation can improve AI visibility by up to 40%, with the addition of statistics and cited sources producing some of the largest individual lifts. BrightEdge found that sites implementing structured data and FAQ blocks saw 44% more AI citations. These are not trivial numbers. The research is peer-reviewed and the methodology is sound.
What the research does not address is crawlability. Every study in this category was conducted on server-rendered content. The assumption - not explicitly stated, because it seemed obvious at the time - is that the AI system being optimised for could actually read the page. For a large proportion of modern web infrastructure, that assumption does not hold.
There is also a well-meaning proposal that has consumed significant attention: llms.txt, a plain-text file in your root directory listing your pages for AI systems. The intent is reasonable. The effect is not measurable. An audit across over 1,000 domains found zero visits from GPTBot, ClaudeBot, or PerplexityBot to the llms.txt file over a thirty-day period. No major AI company has officially adopted it as a standard. It is easy to ship, and there is no published data showing it lifts citation rates.
The issue with llms.txt is that it addresses the wrong layer. It assumes AI crawlers need a map. They don't - they already have your sitemap. What they need is content they can read when they arrive. A file listing your pages does nothing for a page that returns an empty div.
GEO is a content strategy built on a crawl infrastructure most sites never fixed. The content work compounds, but only once the crawler can get through the door.
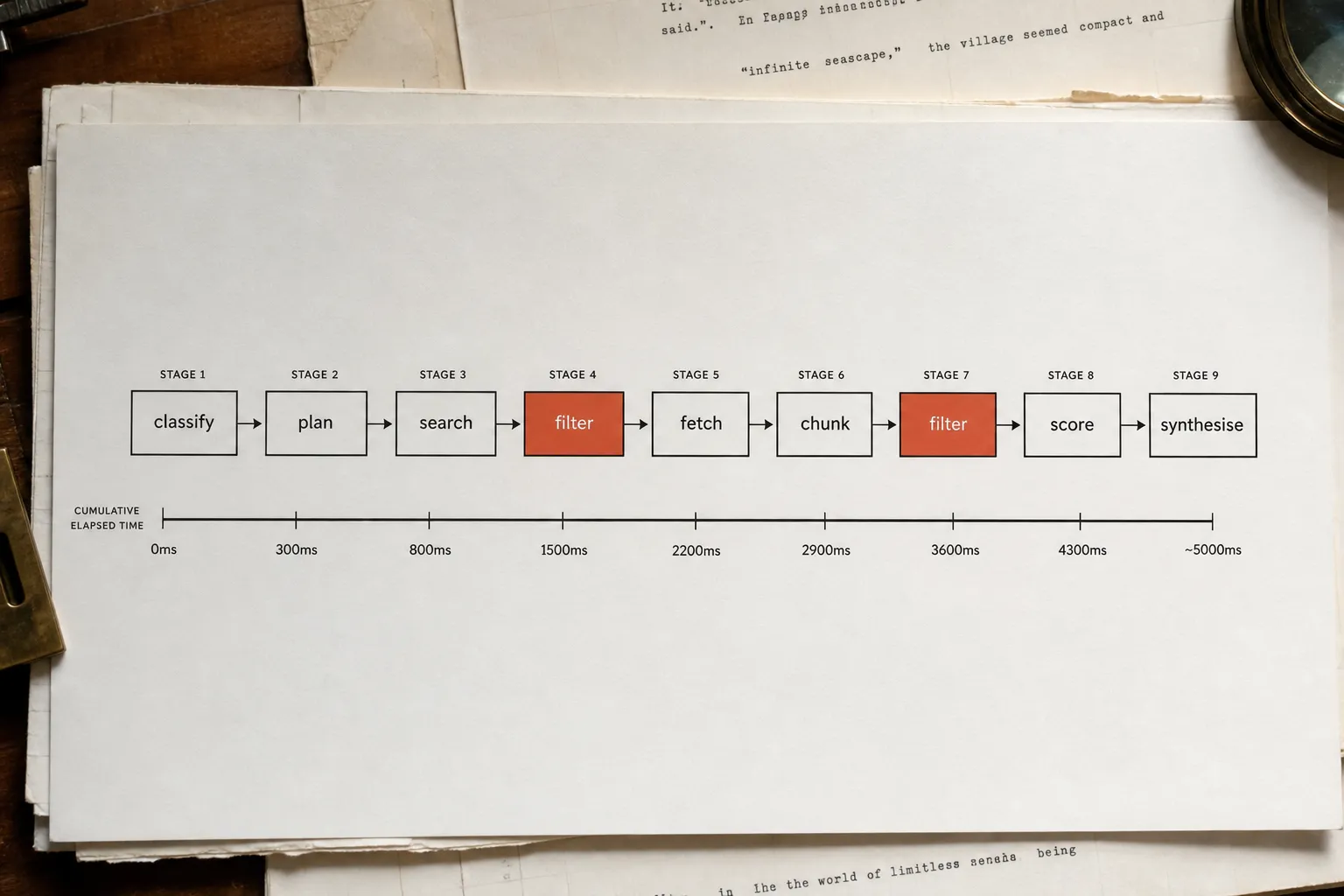
04How agentic pages work at the edge.
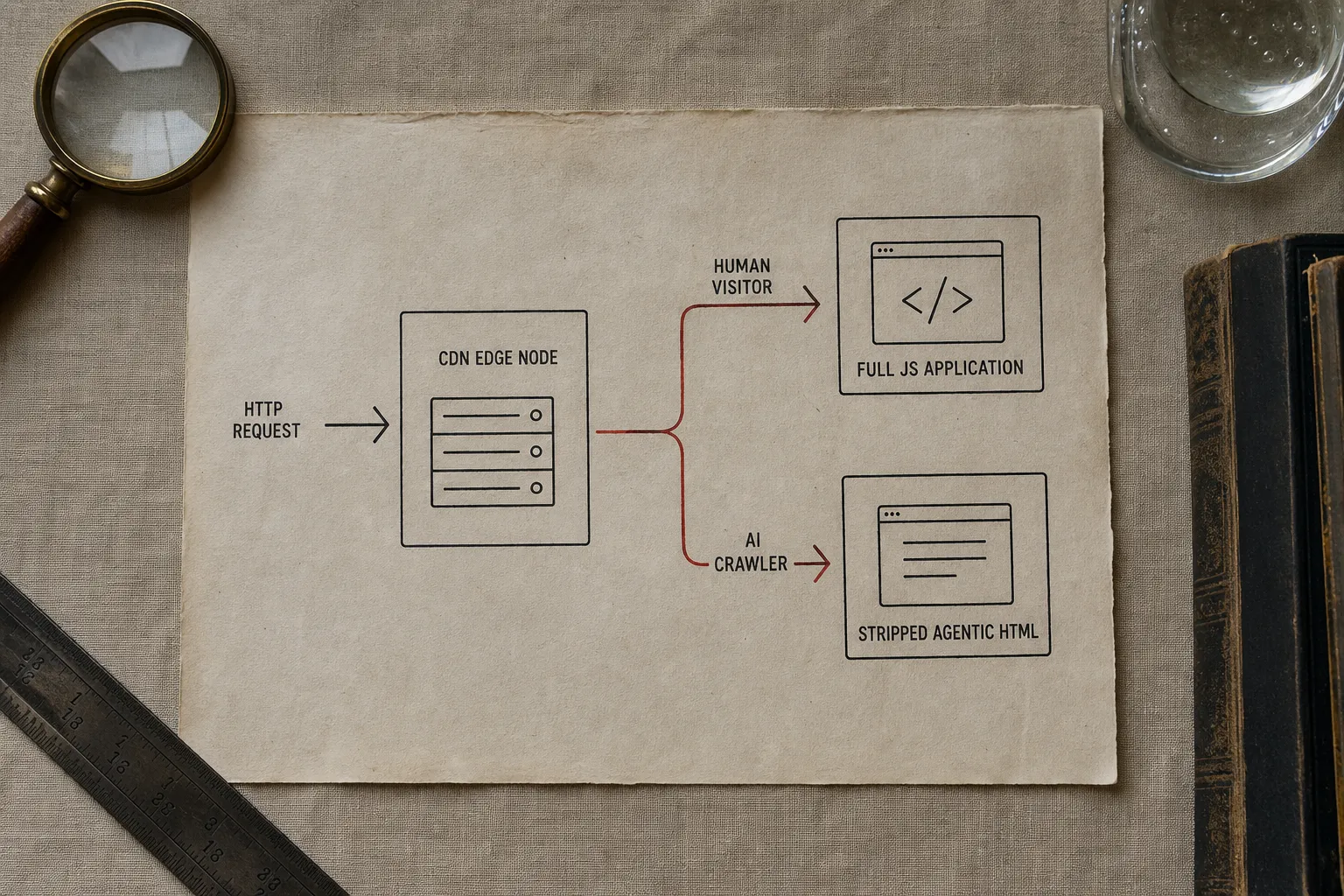
AI crawlers identify themselves with documented user-agent strings. GPTBot, OAI-SearchBot, ChatGPT-User, PerplexityBot, ClaudeBot - these are all detectable at the network edge before a request reaches your origin server or your JavaScript rendering pipeline.
The interception logic is straightforward: when an AI crawler hits any URL on your domain, an edge worker identifies the bot by user-agent and routes the request to a pre-rendered, stripped-back variant of the page. The standard rendering pipeline is not invoked. The crawler receives machine-readable HTML - structured headings, semantic markup, citable content - within the one-to-five-second window it allocates per request. The human-facing page is untouched. No framework migration. No server-side rendering overhaul. No changes to the existing codebase.
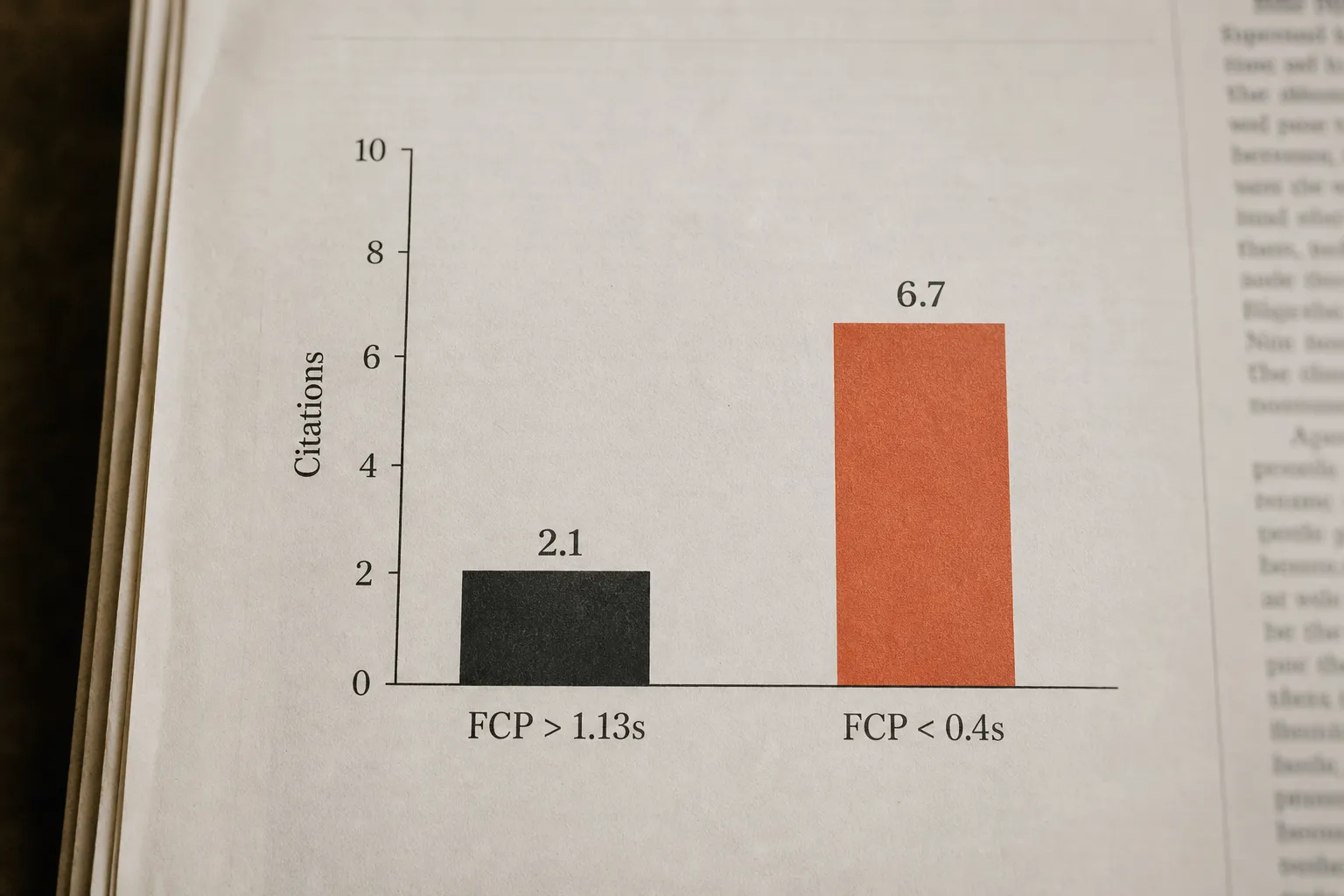
This is what Klove calls an agentic page. The structure is deliberately minimal: the product name and category in the first heading, a plain-prose summary, the information hierarchy the AI came to extract, relevant structured data, and links to supporting evidence. No navigation overhead, no decorative JavaScript, no lazy-loaded content gating the substance. Pages served this way land well under the first-contentful-paint threshold at which citation rates are measurably higher. Delivery speed is not incidental - it is the mechanism.
The human-facing site can remain exactly as it is. Agentic pages operate as a parallel layer, not a replacement. They are also structured for the next version of the problem: interactive elements and navigable markup that AI browser agents can traverse programmatically.
05The citation gap is now measurable.
The distribution of AI citations is concentrated. The top 4.8% of URLs appearing in ChatGPT answers account for the bulk of citations - and virtually all of them serve in-depth, server-rendered, machine-readable content. This is not a coincidence. It is a selection effect produced by crawlability.
Pages with sequential heading hierarchies earn 2.8 times more citations than those with fragmented structure, according to AirOps 2026 research. That structural advantage is only accessible if the crawler can read the headings in the first place. An H2 inside a React component that never hydrates within the timeout window does not exist to the crawler. The heading hierarchy is irrelevant if the page is dark.
AI Overviews now appear in 25% of Google searches, up from 13% in March 2025. The window for citation is widening, not narrowing. Brands cited in AI Overviews earn 35% more organic clicks and 91% more paid clicks compared to brands that rank but are not cited. Being present in the answer is worth more than being present on the results page.
We've seen this split sharpen across sites that serve clean HTML to AI crawlers - whether through server-side rendering or edge-served agentic pages - versus those that don't. The content quality gap between the two cohorts is often smaller than expected. The delivery gap explains most of the citation difference.
Only 30% of brands maintain visibility from one AI answer to the next. The citation gap does not close by writing better content alone. It closes when the crawler can read what you wrote.
06Three things to fix this week.
These are ordered by leverage, not by effort.
1. Audit your crawl logs. Pull your server logs and search for GPTBot, OAI-SearchBot, ChatGPT-User, PerplexityBot, and ClaudeBot. Note which pages they are hitting and what status codes they are receiving. If your analytics show no AI crawler activity at all, that is the finding - not a gap in the data. Your site may be returning errors on bot requests, or the bots may have deprioritised your domain after previous empty responses.
2. Run the JavaScript-disabled test. Open your homepage, pricing page, and top product pages in a browser with JavaScript completely disabled. What remains is roughly what AI crawlers receive. If your core value proposition disappears - if the page is blank or shows only nav scaffolding - that is your current citation floor, not a technical debt item to schedule for Q3. It is active and ongoing.
3. Serve stripped-back HTML to AI crawlers at the edge. Implement edge worker logic to detect AI user-agents and route them to pre-rendered HTML. Alternatively, Klove's agentic page infrastructure handles the interception and serving automatically - no framework changes, no origin modifications - and builds the structured parallel pages from your existing content. The agentic page layer goes live without touching the site your human visitors use.
See what AI crawlers see when they hit your site.
Klove crawls your pages the way GPTBot does and shows you exactly what they find - then serves agentic pages that fix it.
07Where agentic web infrastructure goes next.
The current version of the problem is about citations. The next version is about actions.
McKinsey projects AI agents could mediate between three and five trillion dollars in commerce by 2030. Google's Universal Checkout Protocol, launched in February 2026, lets users complete purchases without leaving AI Mode. Ninety-three percent of AI Mode sessions currently end without a website visit - the AI answers the question without sending the user anywhere. But AI browser agents - ChatGPT Operator, Gemini's agentic features - do browse. They navigate on behalf of users, find the right product, and complete the action.
The question shifts from "can the crawler read my page" to "can the AI agent navigate my site, find what it needs, and execute." A stripped-back agentic page built for citation is a foundation. The full version includes structured actions, navigable landmarks, API endpoints, and interactive elements built for non-human traversal - a site that an agent can move through purposefully, not just extract a paragraph from.
The sites that will hold ground in AI-mediated commerce are those that treat agentic infrastructure as a first-class requirement now. The ones that wait are not just missing citations today. They are letting AI agents form habits on competitor pages - and those habits are not easy to displace once they are set.

Prior to founding Klove, Michael spent over a decade at the intersection of engineering, growth marketing, and revenue operations - building GTM systems for high-growth B2B SaaS companies.