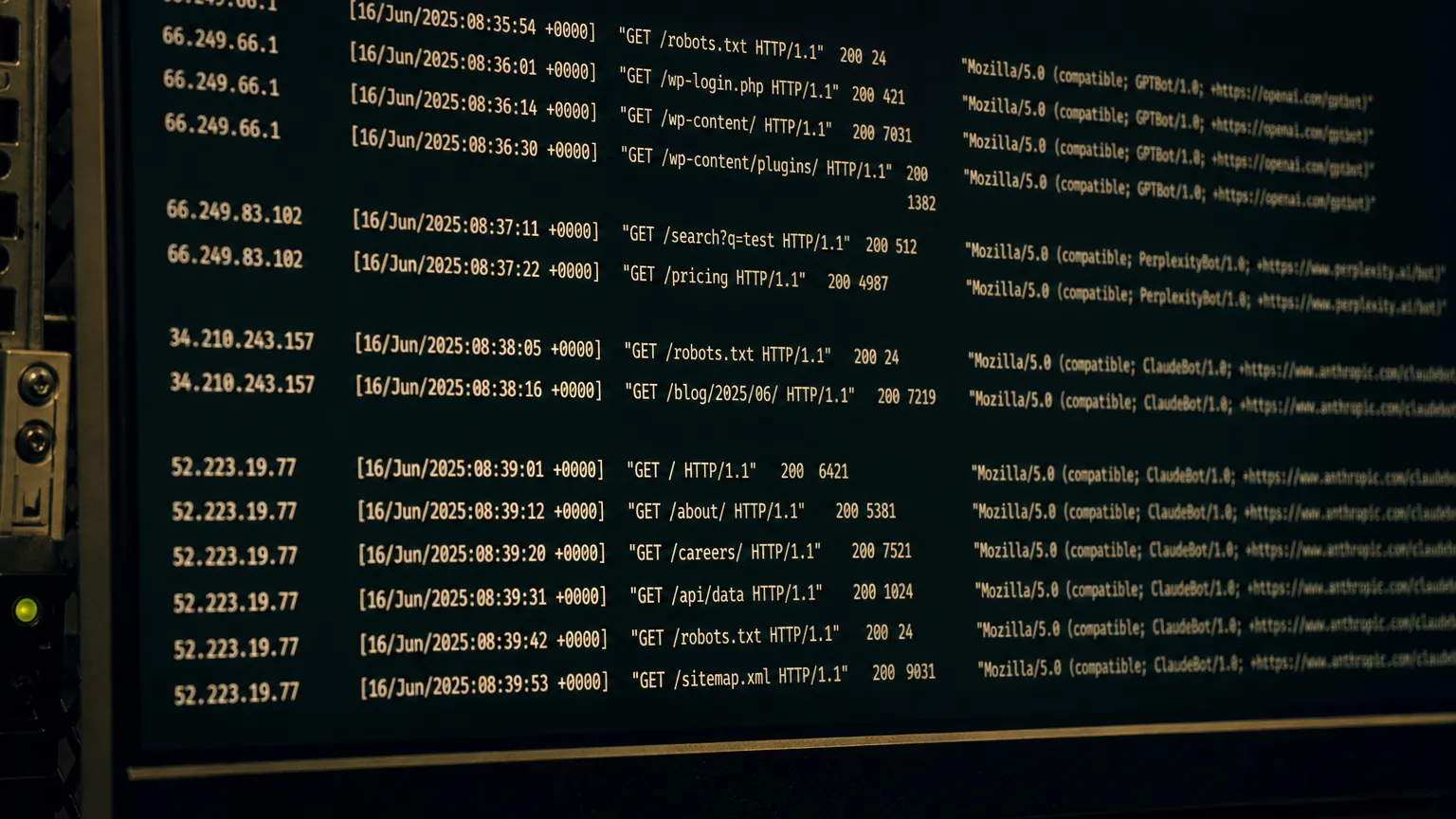
The interface tells a simple story when you hit enter in ChatGPT. One model, thinking, searching, reading, answering. That story is theatre. What runs underneath is a nine-stage pipeline of small specialised models, parallel HTTP fetches, vector scoring, two gated filters, and a synthesis step where the frontier model is handed curated context and told it did all the work itself. Roughly 63% of candidate pages never survive the fetch gauntlet alone, and that is only one of seven places where content gets eliminated before the model generates a word.
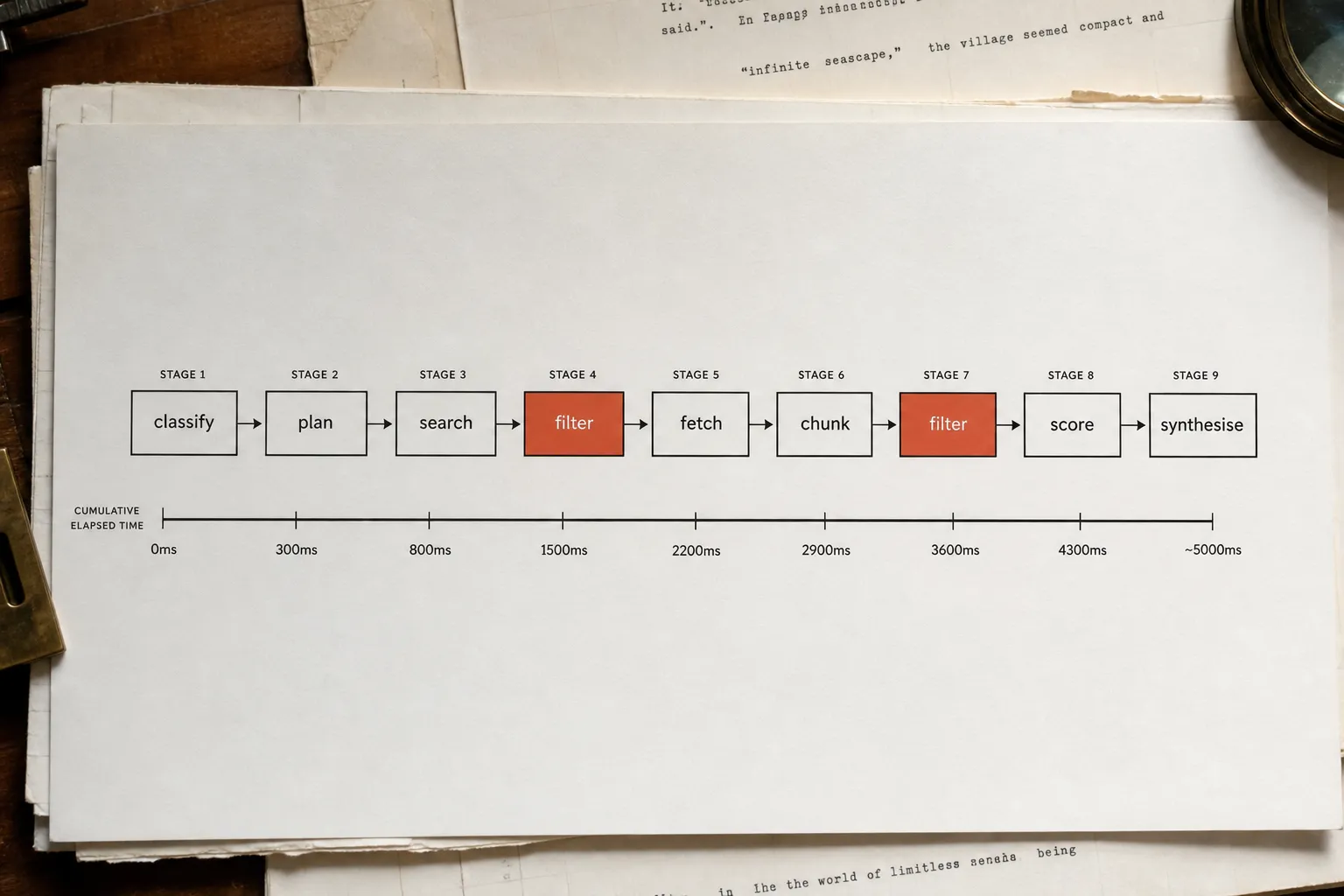
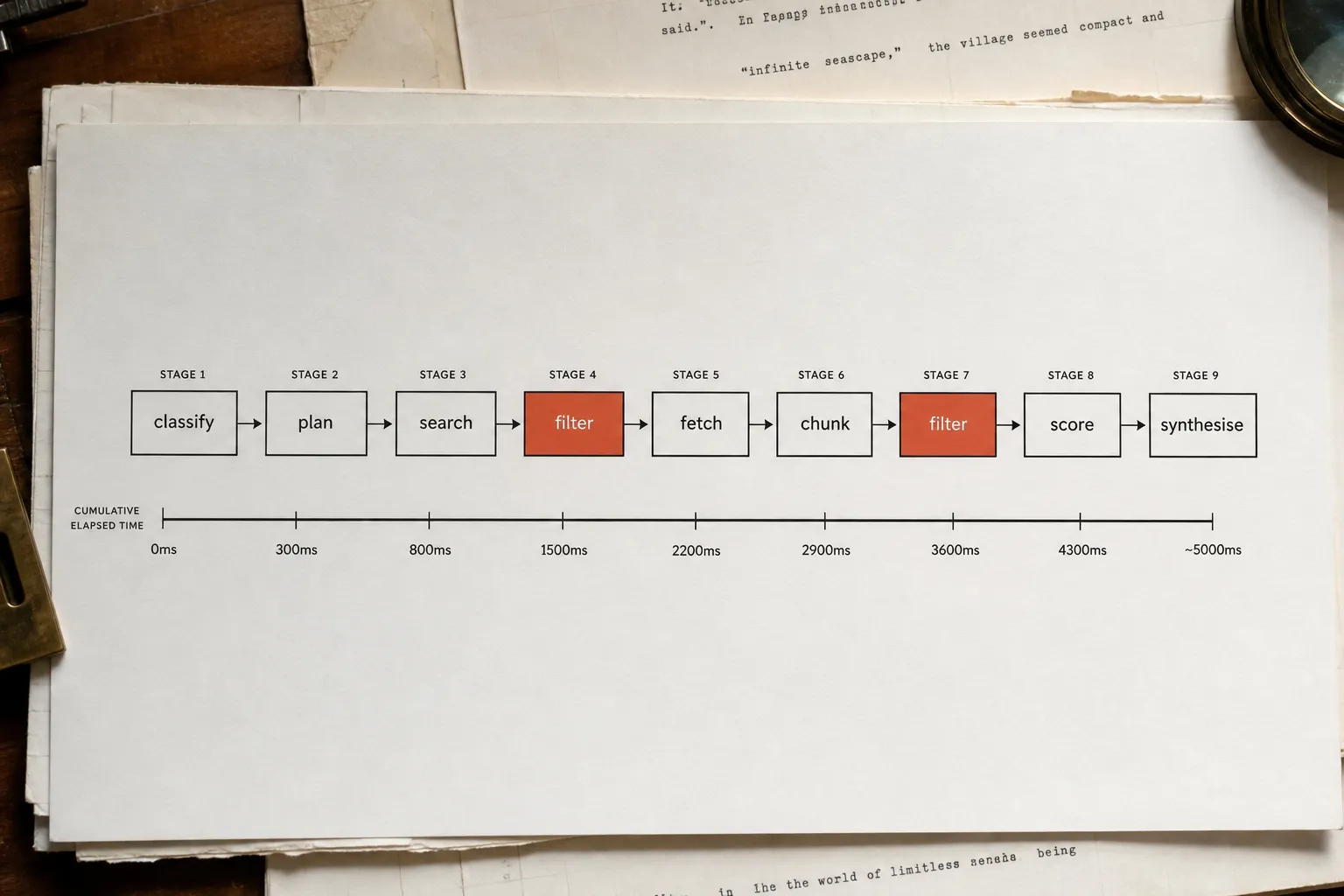
The shape of the pipeline: classify, plan, search, filter, fetch, chunk, score, filter, synthesise. About five seconds in the ideal case. Here is what happens at each step.
01The first checkpoint: classification.
The first model to see your prompt is not GPT 5.2. It is a tiny classifier called the Sonic Classifier, identified in network logs as snc-pg-sw-3cls-ev3, part of an internal system labelled "sonic". Its budget is brutal: it runs in roughly 10 milliseconds because it fires on every single prompt submitted to ChatGPT.
The classifier returns three probability scores summing to 1:
no_search_prob: the frontier model can answer from training data alonesimple_search_prob: a single search will probably sufficecomplex_search_prob: this needs multiple iterative searches
The thresholds are calibrated for efficiency. no_search_threshold sits at 0.2. If no_search_prob exceeds that, GPT 5.2 answers from training data and the pipeline stops there. Zero retrieval. Zero chance for any live page to be cited, regardless of how well-optimised it is.
This is the most important checkpoint most content teams have never heard of. A meaningful share of prompts never triggers retrieval at all. "Capital of France?" Done. No fetch, no candidate ranking, no citation.
If the classifier returns simple or complex, control passes to the next model. The classifier appears brittle. If it times out or fails, the system defaults to passing the query forward anyway. The next model is the smarter, slower backup.
02Planning and query rewriting.
The orchestration model is called Thinky, identified in the event stream as alpha.sonic_thinky_v1. It is almost certainly a small distilled or fine-tuned model. It has to be, because it runs the entire retrieval orchestration and needs to be cheap enough to fire on every retrieval query.
Thinky's first job is rewriting your prompt into search queries. Most people picture ChatGPT generating a list of related queries and firing them at Bing. That is only half of what is happening.
Thinky generates queries in pairs. A simple keyword query for Bing, and a semantic query used later for cosine-similarity scoring against retrieved content. The semantic queries are long, intent-weighted strings averaging around 15 words. They are not keyword-stuffed. They are vocabulary-stuffed, deliberately, to tilt the embedding vector toward the user's intent.
The mechanism is direct. If your prompt is "CRM software", the embedding splits roughly 50/50 between "CRM" and "software". The model cannot know which dimension you care about. So Thinky rewrites it to something like "CRM software pricing comparison enterprise features integrations review", encoding buyer intent directly in the vocabulary and pulling the vector into the right cluster.
For complex queries, Thinky does not make a single pass. It enters what looks like a Recursive Planner Loop: search, evaluate, decide more is needed, search again. The search_turns_count field in the logs has been observed reaching 3.
Thinky's queries are also personalised. The classifier carries num_messages history and context vectors forward into Thinky's input. Ask "best CRM" after twenty minutes of conversation about enterprise security and your queries weight toward compliance. Ask the same question after twenty minutes about cheap email marketing and your queries skew toward price. Two users asking identical questions get different query sets, different candidate pages, and different final answers.
Static citation-tracking tools that query ChatGPT from clean, context-free accounts are showing you a generic-default reality that does not exist for actual users.
03SERP retrieval and the first gate.
Once Thinky has its query pairs, the simple keyword queries fire at Bing, which handles around 90% of ChatGPT's web traffic. All queries run in parallel. All SERP fetches run in parallel. The pipeline typically pulls the first five pages of results per query, producing roughly 50 candidate URLs per simple search. SERP retrieval takes about 500ms to 1.5 seconds in the ideal case.
Fifty candidates is too many for the rest of the pipeline. Gate 1 filters them to 10 to 20, using metadata only. No page content has been fetched yet. Selection is based on the original query, the simple search query, page title, meta description or SERP-displayed snippet, URL, sometimes date, and sometimes structured-data signals if you have schema markup in place.
Thinky also factors in domain diversity, known preferred domains, and trust signals at this stage.
Pages that fail Gate 1 are dumped and never seen again by the rest of the pipeline. They may still appear as "Sources" in the UI, but they did not contribute to the answer. Total elapsed time at this point: under 2 seconds.
04The fetch gauntlet: where most pages die.
The 10 to 20 survivors of Gate 1 are now fetched in parallel with a hard timeout of around 2 seconds. This is where most content disappears.
The failure modes are consistent. TTFB over 1 second: content gets truncated and the bot may receive only the <head> section, with the body never arriving. TTFB over 2 seconds: the connection is severed. Redirects are not followed by most AI bots, ChatGPT in particular. Hit a redirect and the bot leaves. Client-side rendered content is invisible because AI crawlers do not execute JavaScript. The DOM you see in your browser does not exist for the bot. HTML bloat kills throughput: typical enterprise pages carry a content-to-code ratio of 2 to 5%, meaning 95 to 98% of what the bot has to parse is scaffolding.
Across our own tracking, roughly 63% of fetched pages do not make it through this stage.
Whatever survives gets parsed and split into roughly 128-token chunks of around 100 words each. There is likely a hard ceiling on total chunks per page, so longer pages do not receive full coverage. All chunks for all surviving pages then go to the GPU for embedding. Total elapsed time at this point: approximately 4.3 seconds.
05Embedding, scoring, and the second gate.
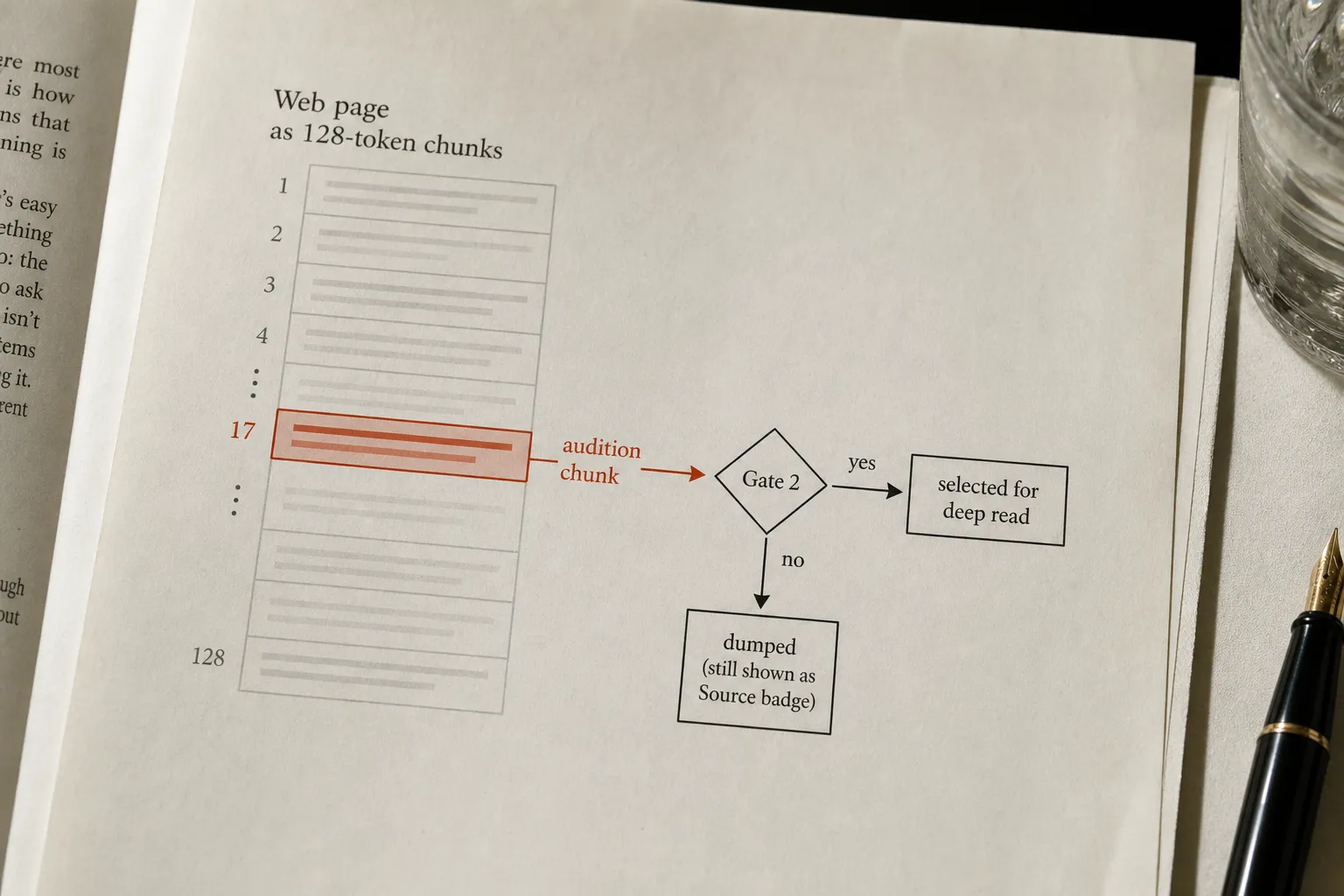
All chunks across all surviving pages are vectorised in a single GPU batch and scored against Thinky's semantic query using cosine similarity. The highest-scoring chunk on each page becomes that page's audition piece. One 128-token slice. The rest of the page is held in reserve but does not influence the next gate.
This batch embedding step takes about 100 to 200 milliseconds. The vector maths is computationally instant. Almost all the time is network hops between services.
Gate 2 is where most content teams get eliminated without knowing it. Thinky now sees the original query, the same SERP metadata from Gate 1, and one audition chunk per surviving page. From the 10 to 20 Gate 1 survivors, it selects 3 to 5 pages for the deep read.
A page can rank in Bing, survive Gate 1's metadata filter, survive the fetch timeout, be parsed and embedded and scored, and still get cut here. The reason is almost always the same: its highest-scoring chunk does not read like an answer to the user's intent.
Pages that fail Gate 2 still get rendered as "Source" badges in the UI. The audition chunk displayed in those badges often contains fragments like "Skip to content" or navigation text. That is the smoking gun. It confirms that scoring is mathematical rather than intelligent, and that the pipeline decided on chunks, not page-level comprehension. Total elapsed time: approximately 4.8 seconds.
06Deep read, mix-in, and final synthesis.
For the 3 to 5 Gate 2 winners, the frontier model does not receive the whole page. It gets a sliding window: the top-scoring chunk plus the chunks immediately before and after, totalling around 300 words per winning page.
A mix-in step runs alongside this. It pulls in pre-synthesised summaries from a VIP lane of high-authority publishers including Time, Forbes, Business Insider, the New York Times, and the New York Post. These summaries do not appear verbatim on the source pages, which strongly suggests they are cached in a local index that bypasses the live fetch gauntlet entirely. High-authority sites get a structural shortcut that ordinary sites do not.
The mix-in also includes Reddit results, likely via API, news results with pre-synthesised summaries, and shopping, maps, or other structured data depending on query type. Total context fed to the frontier model is probably 5 to 6K tokens for a typical search.
GPT 5.2 enters the pipeline only at this final synthesis step. Its system prompt tells it it did all the work itself: the searching, the reading, the comparing. The model is stateless. It has no way to verify this. It checks its system prompt, sees that web-search capability is listed, concludes it is plausible, and generates an answer in voice. The work feels like its own. The illusion is complete.
This is the structural reason the pipeline is so elaborate. Frontier-model inference is expensive. Every token costs real money and real time. The entire nine-stage architecture exists to feed GPT 5.2 the smallest possible amount of highly relevant context rather than the whole web. The theatrical simplicity of the interface is not incidental. It is the product of engineering something that must run in five seconds.
Total idealised latency for the full pipeline: about 5 seconds. Real-world with network congestion, task queues, and timeouts: 5 to 30 seconds. That variability is also why ChatGPT's response time is inconsistent for the same prompt asked twice.
See what AI crawlers actually receive from your pages.
Klove serves stripped-back, machine-readable parallel pages to AI crawlers at the edge, bypassing the fetch timeout and the JavaScript rendering problem entirely. We'll show you what crawlers currently see on your highest-priority pages in a thirty-minute session.
07What this means for content and citations.
Citation rate has a hard ceiling. The classifier at Stage 1 means a share of every prompt never triggers retrieval. No amount of optimisation changes that. You cannot be cited on prompts that do not fire the search pipeline.
Ranking still matters. Gate 1 and Gate 2 both filter candidates pulled from Bing. If you do not rank in Bing, you are not a candidate. Organic search is still the foundation. It just feeds a different consumer.
Speed matters more than for traditional search. Google will eventually crawl a slow page. ChatGPT's fetcher will not. You have roughly 2 seconds of total budget for the connection. Sub-1-second TTFB is required for full content to survive parsing.
Client-side rendering is fatal. Pages requiring JavaScript to render content are completely invisible to the pipeline. React, Vue, and modern SPA sites are functionally absent from ChatGPT's candidate pool unless they serve pre-rendered HTML to crawlers.
One chunk is your audition. Gate 2 sees a single 128-token slice from each surviving page. Whichever chunk scores highest against Thinky's semantic query is the only chunk that argues for inclusion. Pages structured into clear, self-contained answers of around 100 words carry a structural advantage over wall-of-text pages.
Schema and semantic HTML are leverage points at two different stages. Thinky uses structured-data signals and SERP metadata at Gate 1. The embedding model uses semantic HTML structure at chunk time. Both gates reward the same underlying investment.
Static citation tracking is unreliable. Tools that query ChatGPT from clean, context-free accounts return one possible answer from one possible query set. Personalisation, the recursive planner loop, and semantic-query rewriting all introduce variability between users. The result you see in a tracking report may not resemble what any actual user receives.
The pipeline is the playing field. Optimising for AI citation means understanding where the cuts happen, not chasing a generic notion of "AI SEO" that treats the black box as a single step.

Prior to founding Klove, Michael spent over a decade at the intersection of engineering, growth marketing, and revenue operations - building GTM systems for high-growth B2B SaaS companies.